DSP kernels
These benchmark programs measure the in-cache performance of the following kernels for digital signal processing (DSP):
- Convolution (C)
- Convolution of a sequence of 100 samples with a sequence of 10000 samples.
- Recursive Filtering (RF)
- Application of a recursive 2nd-order filter to a sequence of 10000 samples.
- Fast Fourier Transform (FFT)
- Prime factor fast Fourier transform of a sequence of 1008 complex samples.
- Sinc Interpolation (SI)
- Resampling of a sequence of 10000 samples via a tabulated finite-length approximation of the sinc function.
I say in-cache because the input and output sequences for each program are small enough to fit in fast cache memory of modern processors, and each program applies its kernel repeatedly to the same sequences. Therefore, these benchmark programs tend to highlight differences in compilers that may be insignificant in applications where inputs and outputs must be loaded/stored to/from slower memory or disk storage.
I call these operations kernels because they often comprise more complex operations in digital signal processing. Given the performance of these kernels, one can often estimate the performance of those more complex operations.
Another important aspect of these four kernels is that they are independent. For example, they differ significantly in their access of computer memory. Such differences imply that the kernels are not redundant. The performance of one kernel does not predict the performance of another, and the results shown below are consistent with this independence.
The implementations of these kernels are efficient. For example, the convolution kernel requires only one load from memory per multiply-add. A simpler and less efficient implementation would require two loads per multiply-add.
Both Java and C++ versions of single- and double-precision kernels are tested. The Java versions were adapted from the DSP package in the open-source Mines Java Toolkit. The C++ versions are as similar as possible to the Java versions.
90% Pure Java?
Between about 1998 and 2003 or so, C versions of these kernels were up to three times faster than Java versions. Then, I would implement the Java versions by wrapping the C versions, using the Java Native Interface (JNI). This 90% Pure Java strategy worked well. Computational kernels for which Java was slow were written in C, and everything else, especially anything object-oriented, was written in Java. This strategy worked best for applications in which most of the time was spent in that small amount of code written in C.
Today, the differences between Java and C++ (or C) performance for these benchmarks are less significant. And in some cases, the Java versions are faster. (See results below.) Today, one might use JNI only for wrapping huge software packages such as OpenGL and LAPACK, for which only C or FORTRAN interfaces are available.
Compiling and running
The benchmark programs are contained in four files:
Typically, the C++ programs are compiled with -O2
optimization, as in
g++ -o DspBench -O2 DspBench.cpp
When the Hotspot Java virtual machine (JVM) is used, the Java programs are run with -server, as in
java -server DspBench
The benchmark programs run each of the four kernels three times for a fixed number of seconds.
Benchmark results
These results are computation rates, in MFLOPS (millions of floating point operations per second), so higher is faster is better. The results shown below are the fastest (highest MFLOPS) of the three runs.
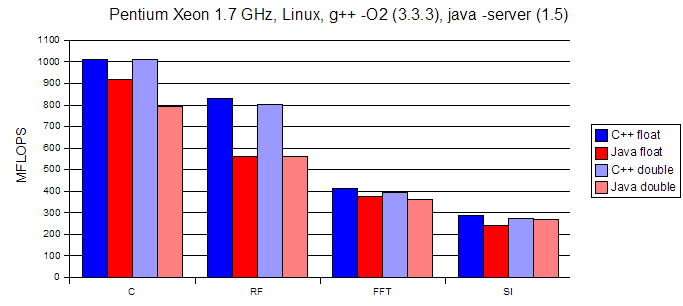
Dave Hale, Colorado School of Mines, 01/11/2007
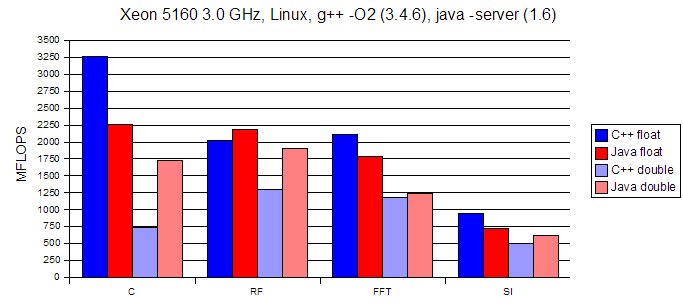
Dave Hale, Colorado School of Mines, 07/04/2006
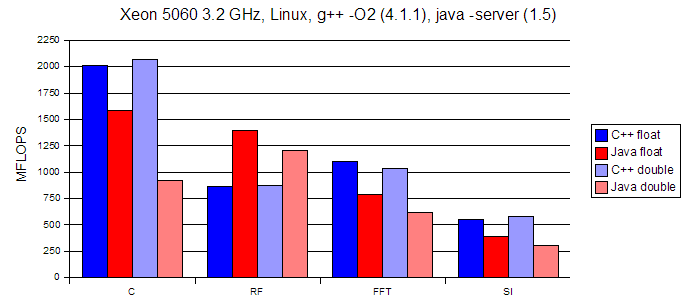
Steve Smith, Colorado School of Mines, 10/11/2005
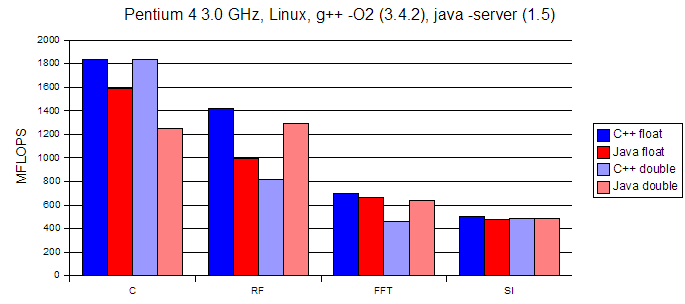
Steve Smith, Colorado School of Mines, 10/11/2005
Steve Smith, Colorado School of Mines, 10/11/2005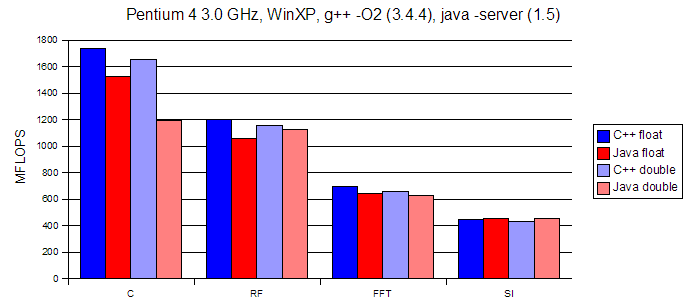
Dave Hale, Colorado School of Mines, 10/15/2005
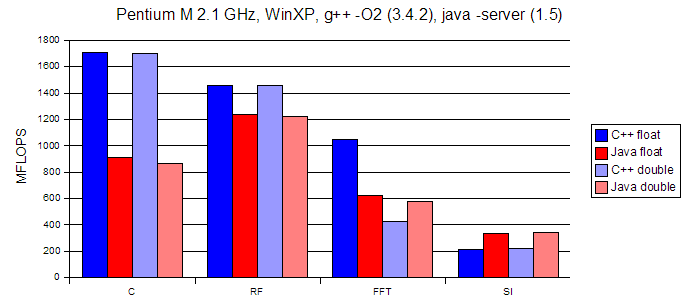
Dave Hale, Colorado School of Mines, 10/18/2005